Spatial Context
When processing a small area of interest, the size of the patch you feed to OmniCloudMask has a large effect on accuracy. Follow these recommendations to get the best results.
When this matters
These guidelines apply when:
You have deliberately chosen a small
patch_sizeforpredict_from_arrayorpredict_from_load_func.Your input scene is small enough that OmniCloudMask automatically reduces the patch size to match the scene dimensions.
You are deciding whether to process imagery at native resolution or downsample for speed.
If you are running large inputs such as Sentinel-2 or Landsat scenes with the default patch_size=1000, you already have plenty of spatial context and can skip this page.
Recommendations
Use at least 96×96 pixels
If you only need to classify a small area, expand the input to the model to at least 96×96 pixels centred on your area of interest. Most of the accuracy gain happens between 32×32 and 96×96. Below 96×96, the model has too little surrounding context and performance drops sharply.
Go larger when you can
Accuracy continues to improve beyond 96×96 but at a slower rate. If your workflow allows larger patches without hurting runtime, use them. The default patch_size=1000 tends to give reliable results. Larger patches also reduce the proportion of overlap pixels when tiling a large scene, which can speed up processing.
Expect thin cloud and cloud shadow to suffer the most from small patches
Clear and thick cloud classes are relatively easy for the model to identify even with minimal context. Thin cloud and cloud shadow are much harder and see the largest accuracy improvements as patch size grows. If your use case depends on accurate thin cloud or shadow detection, err on the side of larger patches.
How the results were produced
Evaluated on the CloudSEN12 High test set (975 scenes). For each scene, the model sees a center patch of a given size, but only the center 32×32 pixels of the prediction are scored against the ground truth. This isolates the effect of spatial context on accuracy for a fixed-size area of interest.
The experiment is repeated at simulated 20m, 30m, 40m, 50m resolution (bilinear downsampling of the native 10m Sentinel-2 imagery) with predictions upsampled back to 10m so all resolutions are compared against the same 10m ground truth.
Metrics
BOA (Balanced Overall Accuracy) is the mean of per-class recall, averaged across all classes. Unlike overall accuracy, BOA gives equal weight to each class regardless of how many pixels it covers, so rare classes like thin cloud and cloud shadow are not drowned out by the dominant clear class.
Dice (equivalent to F1 score) is reported per class.
Results
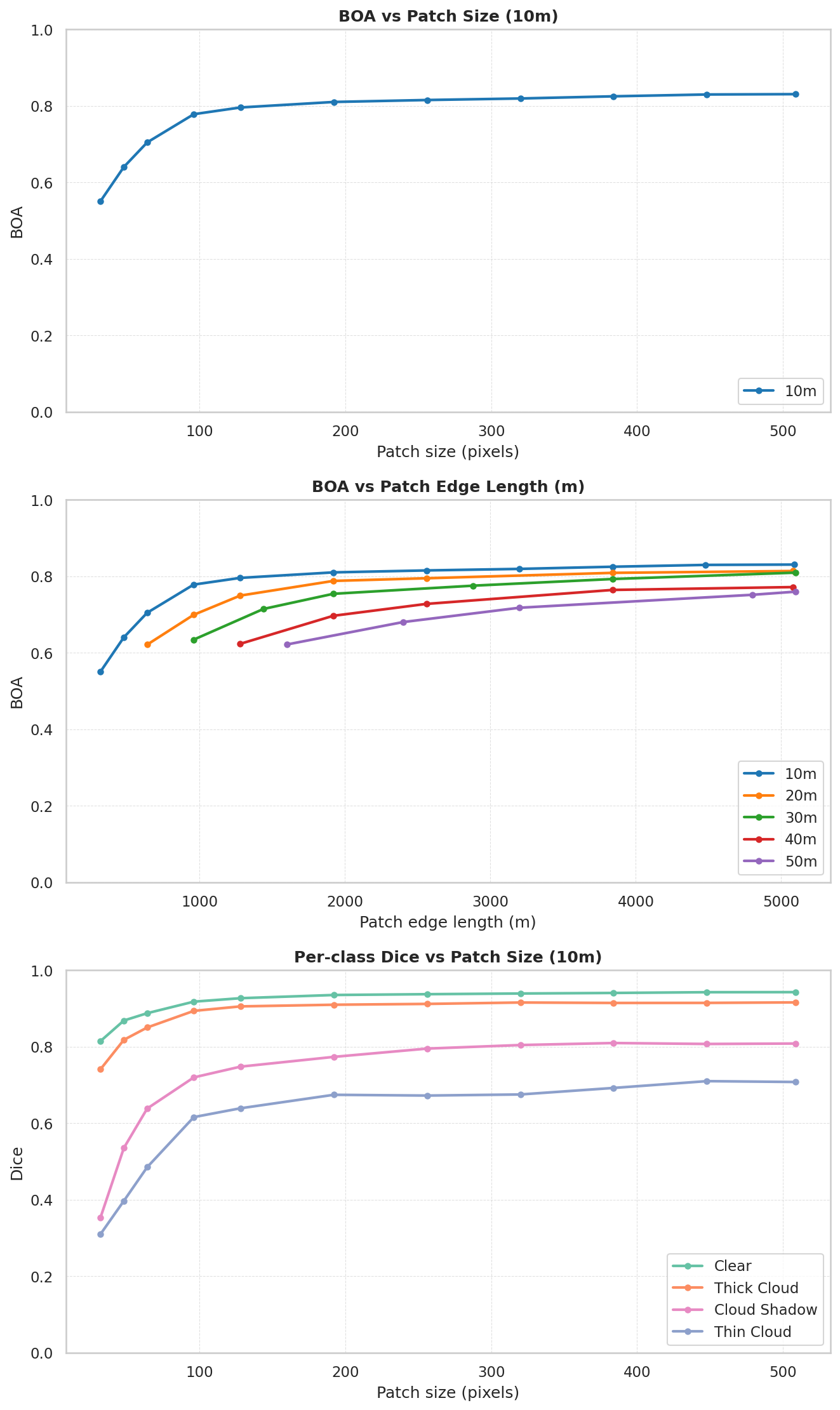
Results generated with benchmarking/spatial_context.ipynb